вЛІиИізЈвЕЕФIDPЯЕЭГжСЩйашвЊОпБИШчЯТСНЗНУцЕФФмСІЃЌВХФмЙЛТњзуИЛИёЪНЮФЕЕЕФжЧФмЛЏДІРэашЧѓЁЃ
гЩгкЮФЕЕБОЩэЖрФЃЬЌЕФЬиЕуЃЌОіЖЈСЫIDPЯЕЭГБиаыФмЁгЙЛзлКЯгІгУМЦЫуЛњЪгОѕКЭздШЛгябдДІРэЕШММЪѕЃЌАќРЈЭМЯёДІЂйРэЁЂOCRЁЂБэИёЪЖБ№ЁЂЮФЕЕНтЮіЁЂЮФБОЗжЮіЁЂЮФЈБОРэНтЕШЃЌЖдгкЮФЕЕжаЕФБъЬтЁЂЖЮТфЁЂБэИёЁЂЭМБэЁЂгЁеТЁЂЧЉУћЕШЖрФЃЬЌаХЯЂНјааЪЖБ№ЁЂЬсШЁКЭНјвЛВНЕФРэНтКЭЗжЮіЁЃ
гЩгкВЛЭЌСьгђЕФЮФЕЕЬиеїВювьКмДѓЃЌЮЊСЫдкСьгђЪ§ОнЩЯДяЕНвЕЮёПЩгУЕФОЋЖШвЊЧѓЃЌIDPЯЕЭГБиаыОпБИЈСьгђбљБОИпаЇбЇЯАФмСІЃЌФмЙЛЩњГЩгХЛЏКѓЕФФЃаЭЃЌТњзувЕЮёГЁОАгІгУашЧѓЃЌЮЊЪЕМЪвЕЮёДДЁєдьМлжЕЁЃ
ЖрФЃЬЌФмСІКЭСьгђбЇЯАФмСІЕШЗНУцЕФвЊЧѓЃЌОіЖЈСЫЭЈгУIDPЯЕЭГЪЧвЛИіИДдгЕФзлКЯадШэМўЯЕЭГЃЌЖдгкММЪѕМмЙЙКЭЯЕЭГЩшМЦЬсГіСЫКмИпЕФвЊЧѓЁЃМмЙЙЩЯЃЌIDPЯЕЭГашвЊФмЙЛМцШнИїжжЩюЖШбЇЯАПђМмЃЌВЂФмЙЛЖдгкИїжждЄбЕСЗДѓФЃаЭЁЂЖрФЃЬЌдЄжУЁрФЃаЭКЭгУЛЇздбЕСЗЕФСьгђФЃаЭЪЕЯжгааЇЕФФЃаЭжЮРэЁЃВЂЧвЃЌФмЙЛвдЭГвЛЕФФЃаЭФмСІВуЃЌЯђЮФЕЕгІгУВуЬсЙЉНгПкЃЌТњзуЩЯВужЧФмЛЏгІгУЕФЕїгУашЧѓЁЃДѓгябдФЃаЭдкжЧФмЮФЕЕДІРэжаЕФМлжЕгыЬєеНШчЯТЭМЃЌЪЧвЛИіГЃМћЕФIDPЯЕЭГФЃаЭММЪѕеЛЁЃПЩвдПДГіЃЌLLMsНіНіЪЧдкздШЛгябдЮФБОетИіФЃЬЌЩЯЃЌзїЮЊдЄбЕСЗЛљДЁФЃаЭЃЈШчКьЩЋИпССВПЗжЃЉЁЃЯрБШгкЮФ
eБОСьгђЕФДІРэФмСІЃЌIDPЯЕЭГжаИќМгКЫаФЕФЙІФмдкгкЮФЕЕЭМЯёКЭЖрФЃЬЌаХЯЂЕФзлКЯДІРэФмСІЃЌАќРЈOCRЁЂБэИёЪЖБ№ЁЂгЁеТЪЖБ№ЃЌвдМАЮФЕЕЗжРрЁЂаХЯЂМьЫїКЭЮФЕЕГщШЁЕШЁЃ

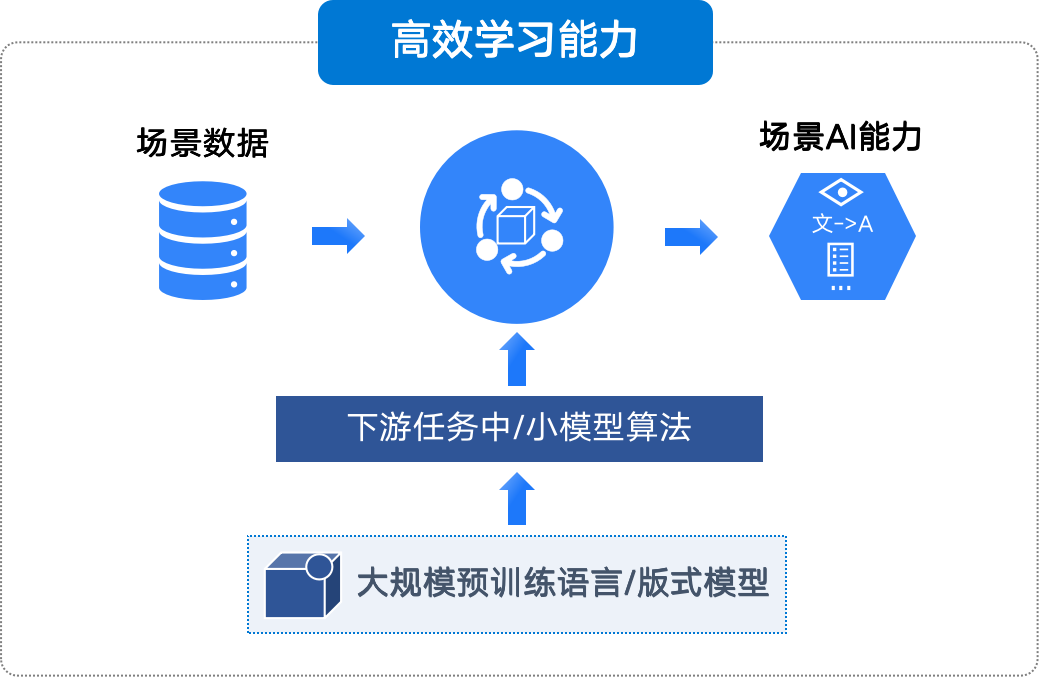
ЭМ2 IDPФЃаЭММЪѕеЛ
вђДЫЃЌЖдгкIDPЯЕЭГЃЌДѓгябдФЃаЭжївЊзїгУЪЧАяжњЬсЩ§ЮФЕЕЮФБОЕФРэНтКЭЩњГЩФмЁЦЁЁСІЃЌЩаЮоЗЈЭъШЋЬцДњIDPФЃаЭММЪѕеЛЁЃДѓгябдФЃаЭдкIDPЯЕЭГЕФжївЊгІгУАќРЈЃК
РћгУДѓгябдФЃаЭЧПДѓЕФЮФБОРэНтФмСІЃЌЬсЩ§ЮФЕЕжаЮФБОаХЯЂЕФЗжРрФмСІЃЌШчЖЮТфКЭЁюЬѕПюЃЌНјЖјЬсЩ§ЮФЕЕаХЯЂМьЫїКЭЮФЕЕЗжРрЕФаЇЙћЁЃ
ЯрБШгкBERTЕШДѓІЮгябдФЃаЭЃЌGPTДѓФЃаЭОпБИЩњГЩЪНЕФЬиЕуЃЌФмЙЛИќКУТњзуЮФЕЕжЊЪЖЪЕЪБЮЪД№ЕФгІгУЃЌАяжњЪЕЯжжюШчЁАгыФуЕФЮФЕЕСФЬьЁБЕШгІгУЙІФмЁўЁЃ
ДѓгябдФЃаЭдкЮФБОаХЁМЯЂГщШЁЗНУцОпБИЧПДѓЕФФмСІЃЌШчДгЬиЖЈЬѕПюЛђЖЮТфжаГщШЁЪЕЬхЁЂЙиЯЕКЭЪТМўЃЌАяжњЬсЩ§ЮФЕЕЙиМќаХЯЂГщШЁФмІЮЁЁСІЁЃ
РћгУДѓгябдФЃаЭЧПДѓЕФРэНтФмСІЃЌФмЙЛЬсЩ§ЮФЕЕжаВЛЭЌЬѕПюЁЂЖЮТфжЎМфЃЌвдМАгыБъІиЁЁзМЬѕПюКЭЖЮТфЕФБШЖдОЋЖШЃЌИФЩЦЮФЕЕБШЖдаЇЙћЁЃДѓгябдФЃаЭдкАяжњЬсЩ§IDPЮФБОДІЁПРэФмСІЕФЭЌЪБЃЌвВУцСйжюЖрЬєеНКЭЗчЯеЃЌжївЊАќРЈЃК
GPT-4ОпгазюДѓ32K TokenЪфШыКЭ25K WordЪфШыЕФвЊЧѓЃЌЯожЦСЫЖдгкГЄЮФЕЕЕФДІРэФмСІЃЌШчМИЪЎЩЯАйвГЕФКЯЭЌКЭБЈИцЮФМўЁЃетОЭвЊЧѓБиаыЭЈЙ§ЧАжУЕФаХЯЂМьЫїЛђЖЮТфГщШЁЕШдЄДІРэЃЌЬсШЁГіДѓЦЊЗљЮФЕЕжаЕФЯрЙиВПЗжЃЌдйЪфШыДѓФЃаЭНјааКѓајШЮЮёДІРэЁЃ
ВЛЭЌгкBERTЕШДѓФЃаЭЃЌGPT(Generative Pre-trained Tranformer)ФЃаЭЪєгкЩњГЩЪНгябдФЃаЭЃЌЖдгкФЃаЭЪфГіЕФаХЯЂЮоЗЈНјааОЋзМЫндДЃЌМДКмЖрЧщПіЯТЮоЗЈзМШЗЛёЕУЁОЪфГіФкШндкЮФЕЕжаЕФОпЬхЮЛжУЃЌетОЭдіМгСЫЪфГіЕФЗчЯеадЁЃдкЖдгкФЃаЭОЋзМЖШвЊЧѓИпЕФГЁОАЯТЃЌШчН№ШквЕЮёГЁОАЃЌЭљЭљМЋаЁИХТЪЕФЗчЯевВЛсДјРДОоДѓЕФЫ№ЪЇЁЃвђДЫЃЌОЭашвЊЭЈЙ§ФЃаЭгХЛЏКЭКѓДІРэЕШЗНЗЈНјаагааЇЙцБмЃЌБмУтЗЧЗЈЪфГіЮЪЬтЁЃ
-
СьгђжЊЪЖибЗІЃЌгАЯьФЃаЭЈаЇЙћ
ЩЯЮФЬсЕНЃЌЮФЕЕЕФвЛДѓЬиеїдкгкЦфСьгђаХЯЂЕФЖрбљадКЭВювьадЁЃЭЈгУДѓгябдФЃаЭЭЈГЃЛљгкЙЋПЊЕФЛЅСЊЭјгяСЯбЕСЗЛёЕУЃЌАќРЈЮЌЛљАйПЦЁЂаТЮХЮФеТЁЂЩчНЛУНЬхЕШЃЌвђДЫЃЌШБЗІЖдгкСьгђжЊЪЖЕФЩюЖШбЇЯАКЭРэНтЁЃЪЕМЪгІЈ}гУжаЃЌБиаыНсКЯСьгђЪ§ОнЛљгкдЄбЕСЗгябдФЃаЭНјаабЇЯАКЭЕїгХЃЌвдДяЕНЪЕМЪвЕЮёЁіГЁОАЕФЪЙгУвЊЧѓЃЌетвВЪЧIDPЯЕЭГБиаыОпБИИпаЇбЇЯАФмСІЕФИљБОдвђЁЃ
-
ФЃаЭВЮЪ§СПОоДѓЃЌЖдЫуСІвЊЧѓИп
ДѓФЃаЭЭЈГЃОпБИНЯДѓЕФВЮЪ§ЙцФЃЃЌШчGPT-3.5га1750вкВЮЪ§ЃЌЖдгкБОЕиЛЏКЭЫНгаЛЏВПЪ№ГЁОАЯТЕФЫуСІГЩБООпгаКмИпЕФвЊЧѓЁЃвђДЫЃЌетаЉЈшГЁОАЯТЃЌБиаыНјааФЃаЭЧсЈСПЛЏДІРэВХФмеце§ТфЕиЪЙгУЃЌШчЭЈЙ§жЊЪЖеєСѓКЭФЃаЭСПЛЏЕШММЪѕЁЃШќВЉНсКЯДѓФЃаЭММЪѕДђдьИпаЇбЇЯАФмСІЃЌЬсЙЉIDPШЋаТНтОіЗНАИШќВЉжЧФмбЇЯАЦНЬЈЖЈЮЛгквЛеОЪНЛњЦїбЇЯАЦНЬЈЃЌЛљгкдЄжУЕФЖрФЃЬЌФмСІКЭИпаЇЕФСьгђЁѕЁЁЪ§ОнбЇЯАФмСІЃЌжЇГжЖдгкЭМЦЌКЭЮФЕЕЕШЗЧНсЙЙЛЏЪ§ОнЕФжЧФмЛЏДІРэЁЃдкдЄжУЖрФЃЬЌ
eФмСІЕФЛљДЁЩЯЃЌЬсЙЉИпаЇЕФСьгђЪ§ОнбЇЯАФмСІЃЌЪЧШќВЉЦНЬЈжЧФмЮФЕЕДІРэЕФКЫаФгХЪЦЁЃШчЯТЭМЃЌЪЧЙигкШќВЉЦНЬЈжЧФмЮФЕЕДІРэЕФКЫаФФмСІНщЩмЁЃ

ЭМ3 ШќВЉЦНЬЈжЧФмЮФЕЕДІРэКЫаФФмСІ
жївЊЕФдЄжУЖрФЃЬЌФмСІАќРЈЃК
ЬсЙЉЭЈгУЮФЕЕЭМЯёЁђМьВтЁЂЧјгђЗжИюКЭНУе§ЁЂЮФЕЕЭМЯёжЪСПМьВтЃЈФЃК§ЁЂЗДЙтЁЂекЕВЁЂХФЦСЁЂЫЎгЁЁЂИДгЁЁЂДлИФЁЂБфаЮЁЂЧаБпКЭОрРыдЖЕШЃЉЁЂИЩШХКЭдыЩљЈLШЅГ§ЕШдЄжУФмСІЁЃ
ЬсЙЉЭЈгУКЭГЁОАOCRЙІФмЁЃЭЈгУOCRжЇГжЖдгкГЃМћЕФЮФЕЕЭМЯёвЊЫиЕФЪЖБ№ЃЌАќРЈЮФБОЃЈДђгЁЁЂЪжаДЁЂЖргябдЃЉЁЂБэИёЁЂгЁеТЁЂЙДбЁКЭЧЉУћЕШЁЃГЁОАOCRЙІФмжЇГжГЌЙ§50жжГЁОАЮФЕЕЭМЯёЕФЪЖБ№ФмСІЃЌКИЧБъзМПЈжЄЁЂЦБОнЁЂБэЕЅКЭЦОЃРжЄЁЃ
ЬсЙЉЭЈгУЕФЮФЕЕДІРэФмСІЃЌАќРЈЮФЕЕИёЪНзЊЛЛЁЂавщНтЮіЁЂАцУцЗжЮіЁЂЮФЕЕНтЮіЕШЃЌвдМАКЯЭЌЕШГЁОАЮФЕЕГщШЁФмСІЁЃ
ЬсЙЉЛљДЁЕФздШЛгябдДІРэЙІФмЃЌАќРЈЮФБОЗжРрЁЂаХЯЂГщШЁЁЂЭЈгУЮЪД№ЁЂЧщИаЗжЮіЕШЁЃ
ШчЧАНкЫљЪіЃЌЮФЕЕОпгаСьгђЬиеїВювьДѓЕФЬиЕуЃЌжївЊБэЯждкВЛЭЌСьгђЮФЕЕЈжЎМфдкжжРрЁЂАцЪНЁЂгяСЯКЭБэДяЗНЪНЕШЗНУцДцдкНЯДѓВювьЁЃвђДЫЃЌИпаЇЕФСьгђЮФЕЕбЇЯАФмСІЃЌЪЧIDPЯЕЭГБиБИЕФЛљБОЙІФмЃЌетЈвВЪЧШќВЉЦНЬЈЕФКЫаФЙІФмжЎвЛЁЃШчЯТЭМЪЧЙигкШќВЉЦНЬЈИпаЇбЇЯАФмСІЕФдРэНщЩмЁЃ
ЭМ4 ШќВЉбЇЁтЯАФмСІ
ШќВЉЦНЬЈIDPбЇЯАФмСІвдДѓЙцФЃгябдФЃаЭКЭЮФЕЕАцЪНдЄбЕСЗФЃаЭЮЊЛљДЁЃЌЭЈЙ§ЯТгЮШЮЮёжа/аЁФЃаЭЫуЗЈЩшМЦЃЌНсКЯСьгђЪ§ОнЃЌИпаЇЩњГЩГЁОАФЃаЭЃЌВЂЭЈЙ§вЛМќЪНФЃаЭВПЪ№КЭAPIЩњГЩЃЌЪфГіГЁОАЛЏЁдAIФмСІЃЌШчЮФЕЕЗжРрЁЂаХЯЂМьЫїЁЂЮФЕЕГщШЁЁЂЖЮТфБШЖдЕШЁЃвРЭаЛњЦїбЇЯАЙІФмЕззљЃЌШќВЉЦНЬЈФмЙЛЬсЙЉЮФЕЕЪ§ОнМЏБъзЂЁЂФЃаЭбЕСЗЁЂФЃаЭВПЪ№КЭAPIгІгУЕШвЛЬхЛЏВйзїЙІФмЃЌжЇГжгУЛЇЭЈЙ§ПЩЪгЛЏвГУцЃЌИпаЇЭъГЩСьгђЮФЕЕЪ§ОнЁћЕФбЇЯАКЭФЃаЭФмСІЈЕФЪфГігыгІгУЁЃСэЭтЃЌЮЊСЫИќКУЕиТњзувЕЮёГЁОАашЧѓЃЌЪЕЯжгывЕЮёЩюЖШШкКЯЃЌШќВЉЦНЬЈжЇГжФЃаЭЪфГіЙцдђКЭAPIДњТыВЙЖЁЖЈжЦЃЌФмЙЛдкЯпЪЕЯжФЃаЭЪфГіИёЪНзЊЛЛЁЂзжЖЮВ№ЗжгыКЯВЂЁЂдыЩљЬоГ§вдМАЦфЫћИпМЖКѓДІРэЙІФмЃЌгааЇНтОіФЃаЭЪфГігывЕЮёашЧѓжЎМфЁАзюКѓвЛЁэЙЋРяЁБЕФЮЪЬтЁЃЮДРДЃЌвзЕРВЉЪЖНЋМЬајСЂзугкН№ЁѓШкЁЂФмдДЁЂЭЈаХЕШаавЕЃЌЮЇШЦЦѓвЕдкШеГЃвЕЮёдЫгЊЁЂЩѓКЫКЭМрЖНЙмРэЁќЁЂаХЯЂМьЫїКЭЗчЯеЙмПиЕШГЁОАЯТЕФЪ§жЧЛЏзЊаЭашЧѓЃЌвРЭаШќВЉжЧФмбЇЯАЦНЬЈЕззљЃЌдкТњзуПЭЁ§ЛЇЪ§ОнАВШЋЕФЧАЬсЯТЃЌЭЈЙ§ИпаЇбЇЯАФмСІЃЌНЋДѓФЃаЭЕШЧАбиММЪѕгыПЭЛЇвЕЮёЪ§ОнЯрНсКЯЃЌЗЂЛгОоДѓЁМаЇФмЃЌЭЈЙ§гывЕЮёГЁОАЕФЩюЖШШкКЯЃЌЮЊвЕЮёИГФмЁЃ






